Abstract
pyMDMA is an open-source Python library that provides metrics for evaluating both real and synthetic datasets across image, tabular, and time-series data modalities. It was developed to address gaps in existing evaluation frameworks which often lack metrics for specific data modalities, do not include certain state-of-the-art metrics, and do not provide a comprehensive categorization.
pyMDMA provides a standard code base throughout all modalities, to make the integration and usage of metrics easier. The library is organized according to a new proposed taxonomy, that categorizes more clearly and intuitively the existing methods according to specific auditing goals for input (e.g., perceptual quality, uniqueness, correlation, etc.) and synthetic data (e.g. fidelity, diversity, authenticity, etc.). In particular, each metric class is organized based on the data modality (image, tabular, and time-series), validation domain (input and synthesis), metric category (data-based, annotation-based, and feature-based), and group (quality, privacy, validity, utility). We provide additional statistics for each metric result to help the user reach more concrete conclusions about the audited data.
In this tutorial, we will begin with a brief overview of the pyMDMA library, followed by three hands-on sessions, each focusing on a different data modality: image, time-series, and tabular. In each session, we will explore practical use cases in depth, demonstrating how to leverage this framework effectively. Specifically, we will cover data preparation and data quality evaluation for both real and synthetic datasets.
Keywords: Data Auditing; Data Quality Assessment; Real Data; Synthetic Data; Image; Time-Series; Tabular
Motivation
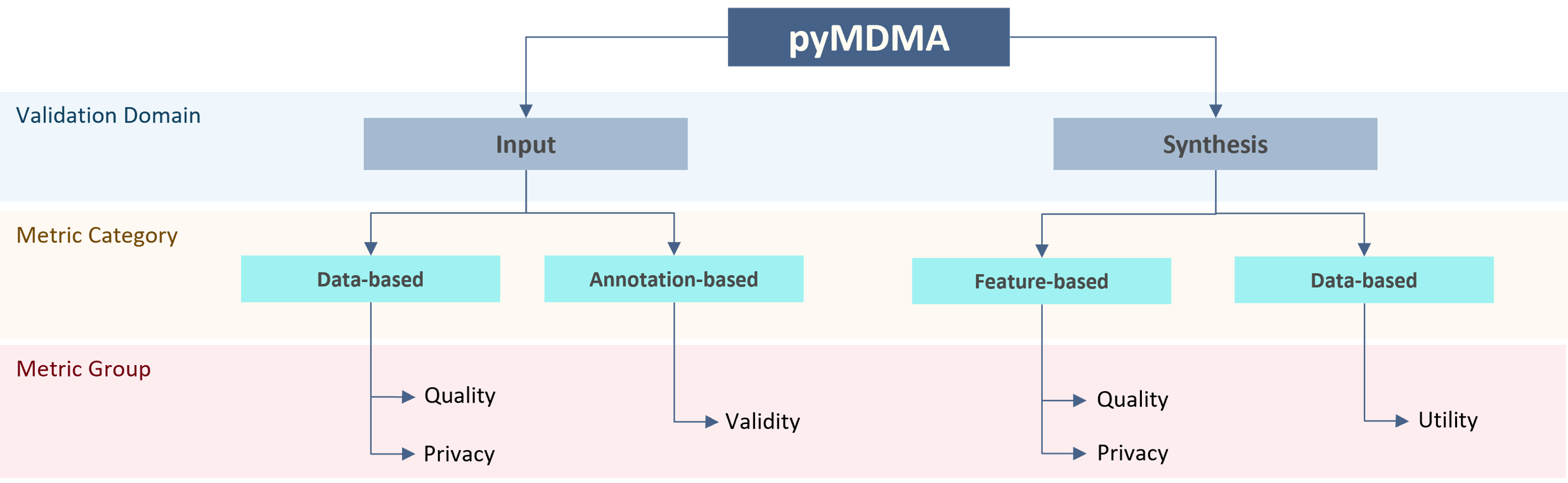
Data quality plays a crucial role in the performance of machine learning models, making it essential to ensure the reliability of training data. With the rapid advancements in generative AI, its applications have expanded across various fields, including industry and healthcare, particularly to address underrepresented scenarios in real-world applications. In data auditing, metrics can be categorized into Input and Synthetic domains, as they serve distinct evaluation purposes. Input metrics assess raw data used in machine learning tasks like classification and regression, measuring fundamental properties such as image contrast or signal-to-noise ratio in time-series data. Synthetic metrics, on the other hand, evaluate the statistical properties of both real and generated datasets, often requiring preprocessing steps like dimensionality reduction to facilitate computation.
Many frameworks exist for evaluating the quality of real and synthetic datasets. However, most focus on a single modality while overlooking others. Additionally, these frameworks have several limitations, including a lack of metrics for specific data modalities, the exclusion of certain state-of-the-art metrics, and the absence of a comprehensive categorization. This tutorial will focus on enhancing the auditing of real and synthetic data using pyMDMA, an open-source Python library designed for evaluating datasets across multiple modalities, including images, tabular data, and time series. pyMDMA provides a unified codebase, simplifying the integration and application of evaluation metrics across different data types. To improve usability, it includes a comprehensive categorization of metrics based on evaluation goals and data requirements, enabling users to easily identify the most relevant metrics for their specific needs. Additionally, hands-on examples in Jupyter notebooks will demonstrate how to utilize pyMDMA effectively and prepare data for evaluation.
Citation
If you use pyMDMA in your research, please cite as follows:
@article{softx2025pymdma,
title = {pyMDMA: Multimodal data metrics for auditing real and synthetic datasets},
journal = {SoftwareX},
volume = {31},
pages = {102256},
year = {2025},
issn = {2352-7110},
doi = {https://doi.org/10.1016/j.softx.2025.102256},
url = {https://www.sciencedirect.com/science/article/pii/S2352711025002237},
author = {Ivo S. Façoco and Joana Rebelo and Pedro Matias and Nuno Bento and Ana C. Morgado and Ana Sampaio and Luís Rosado and Marília Barandas},
}@misc{pyMDMA,
title = {pyMDMA: Multimodal Data Metrics for Auditing real and synthetic datasets},
url = {https://github.com/fraunhoferportugal/pymdma},
author = {Fraunhofer AICOS},
license = {LGPL-3.0},
year = {2024},
}